就在刚刚,StabilityAI正式发布了下一代文生图模型——。

要知道,也就才发布一个月拐点弯。
而据官博介绍,这次的1.0版本是StabilityAI的旗舰版生图模型,也是最棒的开源生图模型。

杀手小猫

幽灵骑士
别的不说,生图模型最重要的当然就是生图质量。
从官博中统计的数据可以看出,和其它模型相对比,用户更青睐1.0版本生成的图像。
该结果来自StabilityAI在Discord上进行的这几代StableDiffusion模型的偏好测试。
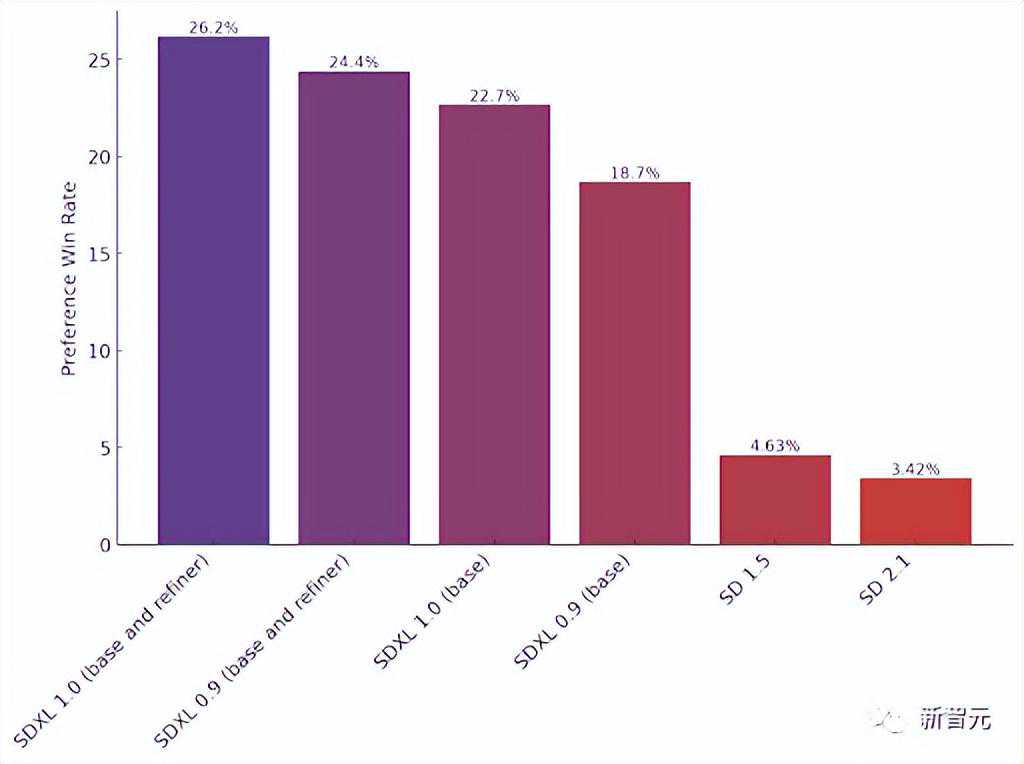
可以看到,上图中纵轴是偏好比例,横轴则是各代SDXL或SD模型。一个月前的0.9版本偏好率是24.4%,低于1.0新版26.2%的偏好。
虽然差距没那么明显,但该说不说,新模型就得比老模型强。
StabilityAI表示,SDXL几乎可以生成任何艺术风格的高质量图像,是实现一顶一逼真效果的最佳模型。
它可以生成各具特色的图像,而不需要模型赋予任何特定的感觉,这样子才能确保风格的绝对自由。
参数方面,在色彩的鲜艳度和准确度方面做了很好的调整,对比度、光照和阴影都比更好,新版本生成的图片全部采用原生的1024x1024分辨率。
此外,SDXL还能生成图像模型难以渲染的概念,如手和文字,还有各种物体的空间排列组合。
比如下面这四个图片。

同时,除了图片生成质量的上调,prompt的设定也变得更加方便。
现在,1.0版本的SDXL只需几个字的prompt就可以生成出复杂、细致、美观的图像。
以往,用户可能需要在prompt中加入「杰作」这类字眼,才能获得满意的高质量图像,现在不用了。
而且还有个小细节——prompt中细微的差别也能敏锐识别的。
比方说当「TheRedSquare」大写的时候,指的是景点「红场」,小写的「redsquare」,指的是红色的正方形。
现在SDXL都可以一步到位的领会意思了。
最大的开放式图像模型
从模型的参数规模上看,是目前开放式图像模型中参数数量最多的。
官方表示,这次采用的是全新的架构,基础模型的参数规模达到35亿,同时还有一个66亿参数大小的细化模型。
完整模型由一个用于潜在扩散的专家混合管道组成:
第一步,基础模型先生成(噪声)潜变量。
第二步,用专门用于最终去噪步骤的细化模型对其进行进一步处理。这里要注意的是,基础模型也可以作为独立模块使用。
这种两阶段的架构可确保图像生成的稳健性,而不会影响速度或者使用过多的计算资源。
可以在配备8GBVRAM的消费级GPU上运行,也可以在就绪的云上运行。
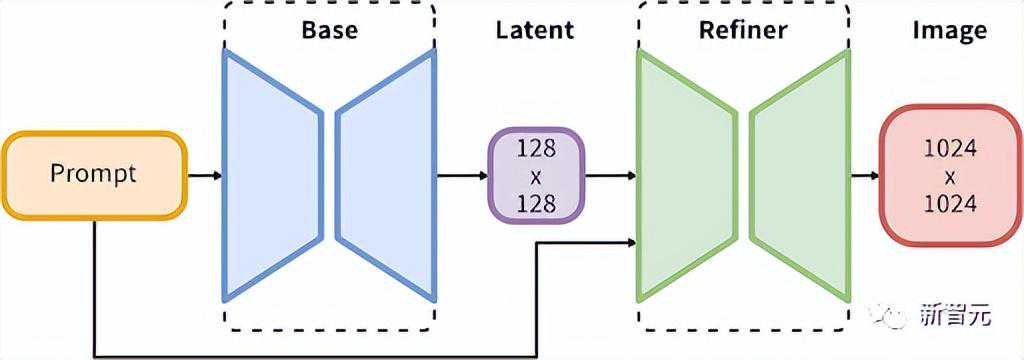
有了,根据自定义数据对模型进行微调比以往此前的版本都要容易。
自定义LoRA或是检查点的生成不需要太多的数据处理。StabilityAI目前正在利用专门用于SDXL的T2I/ControlNet来构建下一代的特定任务结构、样式和组成控制。
官方表示,这些功能目前处于测试预览阶段。


其实从6月份开始,StabilityAI一直在预览的功能,还发布过一个仅用于研究的版本,目的就是展示该模型的全新功能。
官方表示,和之前的SDXL模型相比,的增强功能包括改进过后的图像提炼过程,可以生成更鲜艳的色彩、光照和对比度。
还引入了微调功能,使用户能够轻松创建高度定制的图像。

使用方法
而想要使用最新的也非常简单。
1.在Clipdrop上体验。
别忘了,下面还有很多风格样式可选。
2.在StabilityAI的GitHub页面获取的权重和相关源代码。
3.在StabilityAI平台上通过API使用。
4.在AWSSagemaker和AWSBedrock上获取。
5.可以加入StableFoundationDiscord进行SDXL模型的实时测试。
6.DreamStudio也提供用于图像生成。
参考资料: